The concensus algorithm used for Ethereum is called Ethash. Ethash is a proof of work (PoW) algorithm, modified from the Bitcoin PoW algorithm. The algorithm is needed to secure the blockchain, by making it very difficult to change it. There is a very good blog post that gives a simple explanation of why proof of work is needed.
Design
Ethash is designed to make is very easy to verify if a proof is correct. It’s also designed so that mining is not easy to optimize, and running it on your own computer should not be too much slower than running it on specialized hardware. This is done by making the algorithm very memory (GPU RAM / VRAM) intensive, and there is not much difference in speed between consumer RAM and specialized RAM in GPU’s. This property is very important, because it decreases the centralization of the network, by allowing more people to participate.
See Ethash Design Rationale for more details on this.
The algorithm
The PoW algorithm works as follows:
- create a seed, based on the current epoch (a new epoch start every 30,000 blocks)
- create a cache filled with pseudo random data, from the seed (the same for everyone)
- mix the block header and a random nonce together with items from cache to create a ‘mix digest’
- if the answer is not correct, we increase the nonce and try again (lots of times)
- if the mix digest is correct, we can send out our proof and collect a mining reward
This mix digest, can then be easily verified by anyone, by taking the block header and nonce and doing the same process to see if we get the same mix digest.
Implementation
For exact details you can visit the Ethash page on the ethereum wiki. I used the python code in the wiki to create a TypeScript implementation, and ended up with the following methods:
- getSeed (blockNumber: number)
- getCacheSize (blockNumber: number)
- getFullSize (blockNumber: number)
- generateCache (cacheSize: number, seed: Buffer): Buffer[]
- hashimoto(cache: Buffer[], header: Buffer, nonce: Buffer, fullSize: number)
We can then verify a block like this:
const seed = getSeed(blockNumber);
const cacheSize = getCacheSize(blockNumber);
const fullSize = getFullSize(blockNumber);
const cache = generateCache(cacheSize, cache);
const {blockNonce, difficulty, mixDigest: headerMixDigest} = block.parsedHeader();
const {mixDigest, result} = hashimoto(cache, block.powHash(), block.blockNonce(), fullSize);
const verified = block.mixDigest().equals(mixDigest) && bufferToBigInt(result) < (2n ** 256n) / block.difficulty();
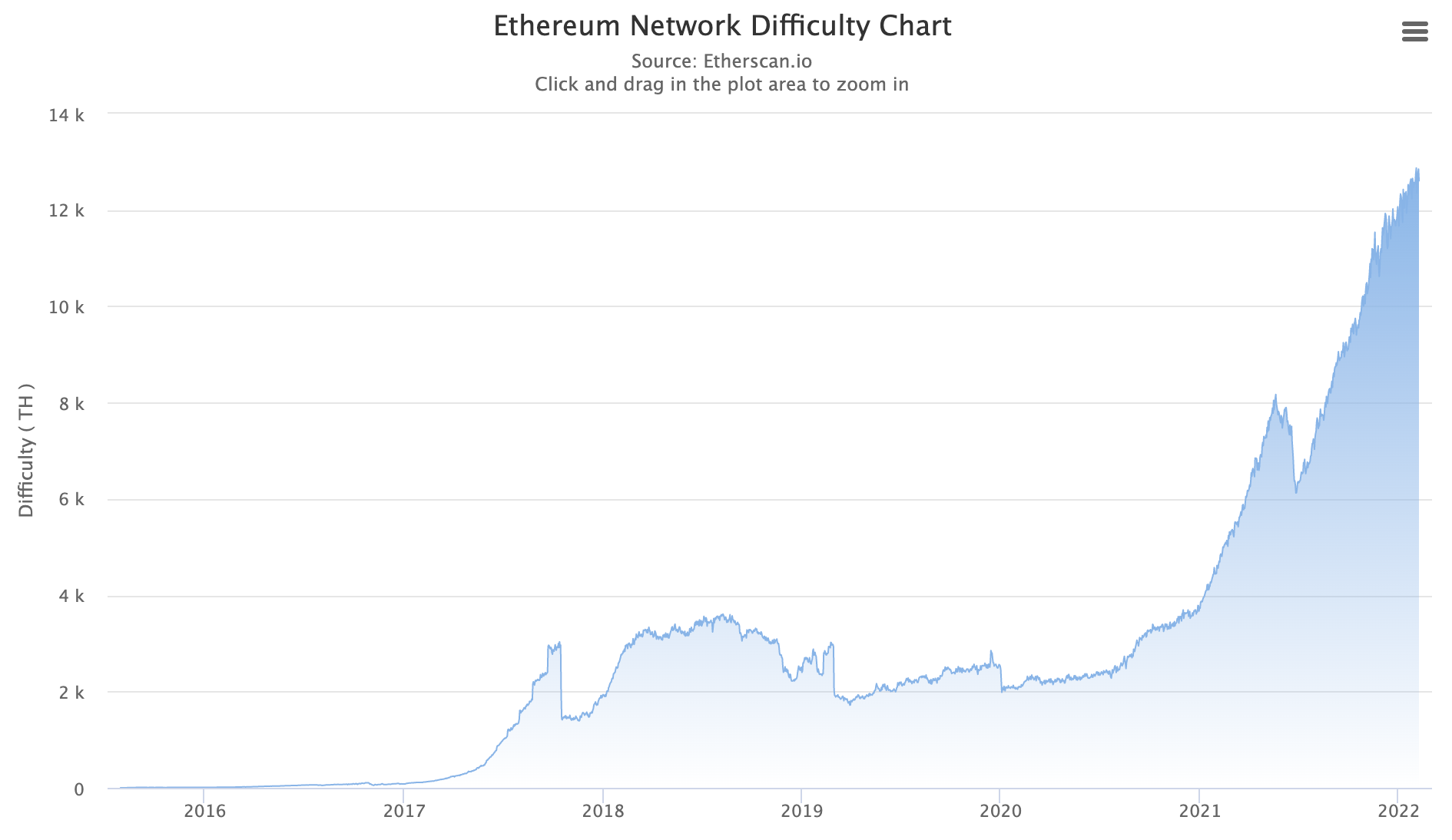
As you can see, we also need to check if the result of the hashimoto algorithm is within the current difficulty. This difficulty is adjusted over time to keep the average block time at 13 seconds. This graph shows the difficulty over the entire lifespan of the ethereum network:
Performance
Creating the cache is the slowest part and takes between 15 and 45 seconds, depending on the cache size. A few years ago the cache size was much smaller (around 16MB), but it has since grown to over 45MB. Luckily though, this only has to be done once every epoch (30,000 blocks). Also, since the cache is only dependent on the epoch number, this can be generated in advance. By using worker threads in Node.js, we can even do this in parallel, without blocking the current thread.
Verifying blocks takes on average 45ms per block. This seems fast, but quickly adds up when syncing the blockchain. It takes around 22 minutes to verify 30,000 blocks. And with around 15,000,000 blocks at the time of writing, this adds up to 187.5 hours. Doing this on several threads while synchronizing could save a lot of time and might be worth implementing.
Improvements
There is only a finite set of possible combinations that can be grabbed from the cache. This set is called the dataset in the documentation, and currently has a size of about 4GB. If you where to precalculate this set, it would be much quicker to do the verification or mining. The dataset takes a really long time to generate though, and according to my calculations, it’s not worth it for just the verification. When implementing the mining algorithm, this might be worth looking into.